脸书团队最新提出了 LCMs:Large Concept Models,是否能成为 LLMs 下一步的进化方向?
现在的 LLMs 都是通过下一个token的概率, 那么tokens 是否过于离散,无法替代人类的思考?人类的思考更倾向于基于概念(比如尤瓦尔赫拉利在《人类简史》中提到的国家/宗教/公司)
下一个“概念”预测能比下一个“单词”预测更加聪明吗?
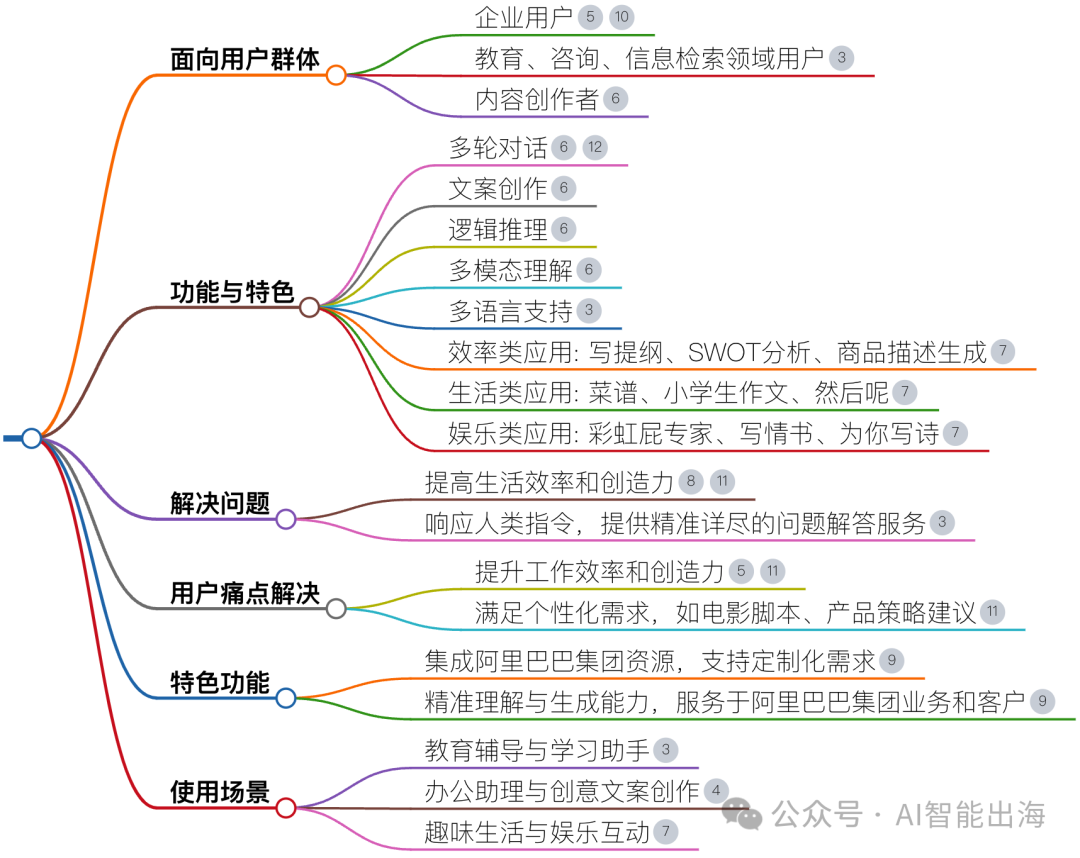
这次我使用腾讯元宝的深度阅读功能来一同深度阅读这篇文章。
![图片[1]-LCM 大概念模型会成为 LLM 大语言模型进化的方向吗?使用腾讯元宝阅读英文论文全流程体验-JieYingAI捷鹰AI](https://www.jieyingai.com/wp-content/uploads/2025/02/1739138545923_0.png)
上传文章后,就可以看到有四个选项,总结、精读、翻译和脑图,其实就相当于将过去的提示词直接转化为一种产品形态,这很腾讯,也确实方便了我们。( LCM论文 PDF 可在后台回复 LCM 获取)
![图片[2]-LCM 大概念模型会成为 LLM 大语言模型进化的方向吗?使用腾讯元宝阅读英文论文全流程体验-JieYingAI捷鹰AI](https://www.jieyingai.com/wp-content/uploads/2025/02/1739138545923_1.png)
我将其中的精华摘录出来。
1、大语言模型彻底改变了人工智能行业。目前成熟的技术是处理 tokens,但是这与人类的思考完全相反,我们是在多个抽象层次上进行思考操作,远远超出单个单词。
2、LLMs 的知识获取高度依赖于数据驱动(就像最近 Illya 提出的数据不够用,预训练将死),将 LLM 扩展到更多语言或者模态需要额外增加(人类原生的或者 AI合成的)的数据来训练。
![图片[3]-LCM 大概念模型会成为 LLM 大语言模型进化的方向吗?使用腾讯元宝阅读英文论文全流程体验-JieYingAI捷鹰AI](https://www.jieyingai.com/wp-content/uploads/2025/02/1739138545923_2.png)
3、目前 LLMs 的格局分为开源模型和闭源模型,但是都基于相同的地城架构:一种基于 Transformer 的、仅解码的语言的模型——用来预测给定前面多个 tokens 的长上下文后,下一个 token 是什么。
4、尽管 LLM 取得了不可否认的成功并且持续进步(但是最近scaling law似乎正在撞墙,逼的奥特曼还得出来说没有墙),但是当前所有的 LLMs 都缺乏人类智能的一个关键特征:在多个抽象层次上的明确推理和规划(reasoning and planning)。
![图片[4]-LCM 大概念模型会成为 LLM 大语言模型进化的方向吗?使用腾讯元宝阅读英文论文全流程体验-JieYingAI捷鹰AI](https://www.jieyingai.com/wp-content/uploads/2025/02/1739138545923_3.png)
5、人脑不仅仅在单词层面运作。我们是自上而下的思考:先在更高的层次规划整体结构,然后逐步添加细节到更低的抽象层次。当然,有其他人也会说 LLMs 虽然看起来是一个一个单词蹦,但其实 LLM 具有一种隐式的层次化的思考,这点辛顿是明确表明 LLM 有智能的。
并且我们在处理和分析信息时,很少考虑大型文档中的某一个词语。而是采用一种层次化的方法:记住在长文中的哪个部分搜索,然后找到特定的信息片段。
6、但是这种信息处理和生成的显式层次结构,在抽象层面上,独立于任何特定语言或者模态的具体实现,在当下的任何 LLM 都找不到。
7、Facebook 的 FAIR 实验室提出一种方法,摆脱了在 token 层面上的处理,更接近于抽象嵌入空间的层次化推理。这个抽象嵌入空间希望能够独立于内容表达的语言或者模态——目标是在纯语义层面对底层推理过程进行建模,而不是在特定语言中的具体实现。这就类似于,如果只用英文语料进行训练,无论如何,大模型上无法理解或者生成中文的。
8、这个基于概念的模型和 LLM 的核心区别在于:在实际中,一个概念通常对应的文本文档中的一句话,而并不是某个单词,这与当前以英文为中心且基于token 的 LLM 技术形成了鲜明的对比。这让我想起了我们中文中的成语,精卫填海,刻舟求剑,按照 token 的理念,这四个字无论如何无法衍生出想要得到的真实含义。
9、LCP 的基本思想是基于任何固定大小的句子嵌入空间。致力于训练一个新的、专门为我们的推理架构优化的嵌入空间。
![图片[5]-LCM 大概念模型会成为 LLM 大语言模型进化的方向吗?使用腾讯元宝阅读英文论文全流程体验-JieYingAI捷鹰AI](https://www.jieyingai.com/wp-content/uploads/2025/02/1739138545923_4.png)
10、LCM 的主要特定有:
在抽象语言和模态无关的层次上进行推理,超越 token 的概念:对底层推理过程进行建模,而不是在特定的某种语言上的具体实现;LCM一次性在所有语言和模态上进行训练,承诺以无偏见的方式提供可扩展性。(某种意义上我认为这是正确的,不论是什么语言,语法单词只是变现形式,含义才是根本,否则也不会有所有的翻译了)
明确的层次结构:人类更喜欢阅读长文;方便人类局部编辑。现在的 LLM 输出基本上一个一个词的蹦,无法编辑。
处理长文本:现在基于 Transformer 模型的 LLM 复杂性与input 的 token 长度呈现二次方指数增长。LCM 能降低这个挑战性。
无与伦比的零样本泛化能力:与LCM预训练和微调所使用的语言或模态无关,它可以应用于由SONAR编码器支持的任何语言和模态,无需额外数据或微调。
模块化和可扩展性:对于现有系统,可以轻松添加新语言或模态。
11、总结
“大型概念模型”(LCM),该架构与当前LLM在两个方面有显著不同:1)所有建模都是在高维嵌入空间中进行,而不是在离散标记表示上;以及2)建模不是特定于某种语言或模式,而是在更高层次的语义和抽象层面上实现。我们将这种表示的一般形式称为“概念”。
LCM表现出强大的零样本泛化性能。在本文中,我们仅使用英文文本来训练模型,并将其应用于其他语言的文本,而无需任何额外的训练数据,无论是已对齐的还是未标记的。LCM在英语以及LLM官方支持的外语平均表现上均优于LLAMA-3.1-8B。
预测下一个句子比预测下一个标记要困难得多。首先,鉴于我们在嵌入空间中操作,并且处于更高的语义层面,可能的句子数量几乎是无限的,而标记词汇通常在10万左右的范围内。其次,即使给定较长的上下文,在选择下一个句子时也不可避免地比选择下一个标记有更多的歧义。第三,通常的固定大小标记词汇上的softmax输出层提供了所有可能的标记连续性的标准化概率分布。
12、感想
不得不说,发布了开源 Llama 模型的 Facebook 依然是具有理想的,这次提出的 LCM 也让人眼前一亮。
这个概念很好理解,比如有维度提升的思路,过去的单词是一维的,现在换成了句子,是二维,未来是什么呢,是段落吗?
这让我想起了电影《降临》中的七文,一种环形文字,你掌握后可以沟通过去和未来。
![图片[6]-LCM 大概念模型会成为 LLM 大语言模型进化的方向吗?使用腾讯元宝阅读英文论文全流程体验-JieYingAI捷鹰AI](https://www.jieyingai.com/wp-content/uploads/2025/02/1739138545923_5.jpg)
基于 token 的 LLM 是为了预测下一个单词可能的概率,那么未来基于概念和意义的大模型是不是就能预测我们的下一个意图。
从 LLM 到 LCM 让我本能的感受到,这个世界在 AI 进化的步调似乎不仅没有撞墙,而且由于我们的无知,还有广袤的未知地等待我们的探索。
下一个 L‘X’M会是什么,模型要大似乎是注定的命运,就好像你要有全知的能力,那就要首先容纳过去所有的知识;那么 X 会是什么,刚开始是语言模型(其实准确点应该叫做 Token 模型),最近提出了概念(Concept)模型,下一步是不是可能是世界(World)模型、故事(Story)模型等等。
回到 LCM 的提出,庆幸的是除了闭源的大模型以外,我们还有开源世界的力量。可以让所有人都知道即将到来的某种科技爆发。